
Nothing is FREAKy about Fast Retina Keypoint descriptors
Recently I have been taking several courses about computer vision in which I was introduced to the many interesting problems and applications of feature detection in images. The first feature detection algorithm I learned about was of SIFT (scale-invariant feature transform), which is one of the most commonly used algorithms used for applications like object recognition, panorama stitching, etc.
Although my course stopped at SIFT, with some literature review, I discovered there was a large variety of feature detection algorithms that suggest equal or greater performance than SIFT. Among these algorithms, the one that caught my attention was the FREAK algorithm, which was first proposed by A. Alahi, R. Ortiz, and P. Vandergheynst at the 2012 IEEE Conference on Computer Vision and Pattern Recognition
How does FREAK work?
Both FREAK and SIFT distinguish features in an image from each other by creating a descriptor for them. You can think of a descriptor as being a mathematical identifier for a feature. Typically we want these descriptors to be rotation invariant and scale invariant so that the same features can be detected in images that are rotated and scaled differently from the original image.
However, whereas SIFT finds features in an image and creates a descriptor them, FREAK only describes them. Another key difference between SIFT and FREAK is that FREAK is a binary descriptor - in other words, the FREAK descriptor is a binary string, which has multiple advantages such as being easier to compare with other feature descriptors (using Hamming distance) and taking up less space.
What makes FREAK special is how it uses a sampling pattern inspired by the anatomy of the human retina. For each feature in the image, we look at a region around the pixel the feature lies in. We apply a Gaussian filter for each receptive field in the sampling pattern, where the sigma value of each Gaussian filter is equal to the radius of the receptive field. To create the FREAK binary descriptor, we need to perform a global training step and then local description steps for each feature.
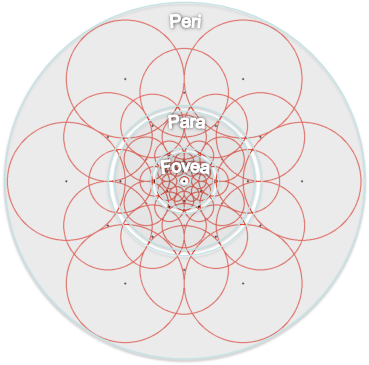 Diagram of the receptive fields of the human retina used in the FREAK descriptor. Source: lahi, Alexandre & Ortiz, Raphael & Vandergheynst, Pierre. (2012). FREAK: Fast retina keypoint. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.
Diagram of the receptive fields of the human retina used in the FREAK descriptor. Source: lahi, Alexandre & Ortiz, Raphael & Vandergheynst, Pierre. (2012). FREAK: Fast retina keypoint. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition.
The goal of the training step is to compute the best pairs of receptive fields that will determine the most important characteristics of a feature. First, we take the values of the Gaussian filters at each receptive field center and compute the differences in intensity for each pair of receptive field centres. In our sampling pattern, we have 43 receptive fields which leads to 903 different combination of pairs. If the difference between a pair is positive, we set one bit in our binary string to 1 and otherwise we set it to 0. Therefore, we get a binary string of 903 bits.
We order the bits from the coursest receptive fields to the finest receptive fields by finding the differences between the larger outermost receptive fields with the smaller innermost receptive fields. After finding the binary strings for each feature, we stack the binary strings on top of each other to make a matrix > D, whose dimensions is n x 903 for n features. Next we compute the mean of each column of D. We pick the columns of D (which correspond to pairs of receptive fields) that have the lowest correlation and thus have a mean value closest to 0.5. After this step, we can choose the best 512 columns that have the least amount of correlation from each other, which determines what our FREAK descriptor will be.
With that, the hardest part is complete. Now we can iterate through each feature and compute its FREAK descriptor based on the best pairs we found in the training step.
Investigating further
Once I understood how FREAK worked, I wanted to see just how effective it was compared to other feature descriptor algorithms. With my peers Asad Jamil and Matthew Dans, we implemented FREAK in Python from scratch and compared its performance with SIFT and BRISK (another popular binary descriptor). Implementations of SIFT and BRISK were taken from the OpenCV-Python library. The results of the investigation and a writeup of our findings can be seen here.